FSx for Lustre Best practices
Amazon FSx for Lustre, built on Lustre, the popular high-performance file system, provides scale-out performance that increases linearly with a file system’s size. Lustre file systems scale horizontally across multiple file servers and disks. This scaling gives each client direct access to the data stored on each disk to remove many of the bottlenecks present in traditional file systems. Amazon FSx for Lustre builds on Lustre's scalable architecture to support high levels of performance across large numbers of clients.
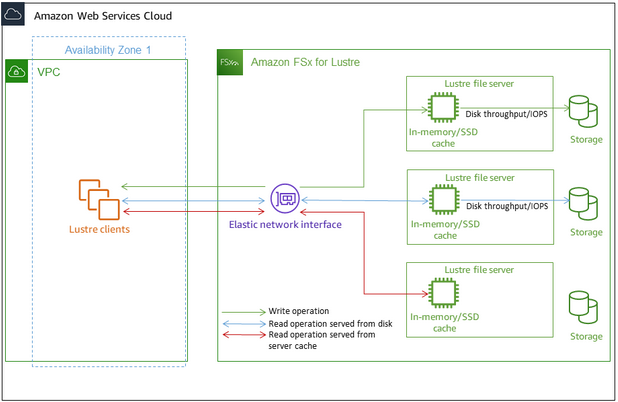
Each FSx for Lustre file system consists of the file servers that the clients communicate with, and a set of disks attached to each file server that store your data. Each file server employs a fast, in-memory cache to enhance performance for the most frequently accessed data. HDD-based file systems can also be provisioned with an SSD-based read cache to further enhance performance for the most frequently accessed data. When a client accesses data that's stored in the in-memory or SSD cache, the file server doesn't need to read it from disk, which reduces latency and increases the total amount of throughput you can drive. The following diagram illustrates the paths of a write operation, a read operation served from disk, and a read operation served from in-memory or SSD cache.
Performance tips
When using Amazon FSx for Lustre, keep the following performance tips in mind.
-
Average I/O size – Because Amazon FSx for Lustre is a network file system, each file operation goes through a round trip between the client and Amazon FSx for Lustre, incurring a small latency overhead. Due to this per-operation latency, overall throughput generally increases as the average I/O size increases, because the overhead is amortized over a larger amount of data.
-
Request model – By enabling asynchronous writes to your file system, pending write operations are buffered on the Amazon EC2 instance before they are written to Amazon FSx for Lustre asynchronously. Asynchronous writes typically have lower latencies. When performing asynchronous writes, the kernel uses additional memory for caching. A file system that has enabled synchronous writes issues synchronous requests to Amazon FSx for Lustre. Every operation goes through a round trip between the client and Amazon FSx for Lustre.
-
Limit directory size – To achieve optimal metadata performance on Persistent 2 FSx for Lustre file systems, limit each directory to less than 100K files. Limiting the number of files in a directory reduces the time required for the file system to acquire a lock on the parent directory.
-
Amazon EC2 instances – Applications that perform a large number of read and write operations likely need more memory or computing capacity than applications that don't. When launching your Amazon EC2 instances for your compute-intensive workload, choose instance types that have the amount of these resources that your application needs. The performance characteristics of Amazon FSx for Lustre file systems don't depend on the use of Amazon EBS–optimized instances.
-
Recommended client instance tuning for optimal performance
a. For all client instance types and sizes, we recommend applying the following tuning:
sudo lctl set_param osc.*.max_dirty_mb=64
b. For client instance types with memory of more than 64 GiB, we recommend applying the following tuning:
sudo lctl set_param ldlm.namespaces.*.lru_max_age=600000
sudo lctl set_param ldlm.namespaces.*.lru_size=<100 * number_of_CPUs>
c. For client instance types with more than 64 vCPU cores, we recommend applying the following tuning:
echo "options ptlrpc ptlrpcd_per_cpt_max=32" >> /etc/modprobe.d/modprobe.conf
echo "options ksocklnd credits=2560" >> /etc/modprobe.d/modprobe.conf
# reload all kernel modules to apply the above two settings
sudo reboot
After the client is mounted, the following tuning needs to be applied:
sudo lctl set_param osc.*OST*.max_rpcs_in_flight=32
sudo lctl set_param mdc.*.max_rpcs_in_flight=64
sudo lctl set_param mdc.*.max_mod_rpcs_in_flight=50
Note that lctl set_param is known to not persist over reboot. Since these parameters cannot be set permanently from the client side, it is recommended to implement a boot cron job to set the configuration with the recommended tunings.
-
Workload balance across OSTs – In some cases, your workload isn’t driving the aggregate throughput that your file system can provide (200 MB/s per TiB of storage). If so, you can use CloudWatch metrics to troubleshoot if performance is affected by an imbalance in your workload’s I/O patterns. To identify if this is the cause, look at the Maximum CloudWatch metric for Amazon FSx for Lustre.
In some cases, this statistic shows a load at or above 240 MBps of throughput (the throughput capacity of a single 1.2-TiB Amazon FSx for Lustre disk). In such cases, your workload is not evenly spread out across your disks. If this is the case, you can use the lfs setstripe command to modify the striping of files your workload is most frequently accessing. For optimal performance, stripe files with high throughput requirements across all the OSTs comprising your file system.
If your files are imported from a data repository, you can take another approach to stripe your high-throughput files evenly across your OSTs. To do this, you can modify the ImportedFileChunkSize parameter when creating your next Amazon FSx for Lustre file system.
For example, suppose that your workload uses a 7.0-TiB file system (which is made up of 6x 1.17-TiB OSTs) and needs to drive high throughput across 2.4-GiB files. In this case, you can set the ImportedFileChunkSize value to (2.4 GiB / 6 OSTs) = 400 MiB so that your files are spread evenly across your file system’s OSTs.